Introduction
On day two of the November 2013 Cheltenham meeting David Pipe drew a blank from his seven runners. For many people this result pointed to the Pipe stable being out of form. But whatever might have been ailing the yard on Saturday had disappeared by Sunday morning, with four winners, including The Greatwood, one of the most competitive handicap hurdles in the calendar. No doubt on Sunday evening the Pipe yard was marked out as one to follow. So what of trainer form, is it possible to identify yards that are in or out of form? In the woefully misnamed ‘Statistics’ section of the Racing Post the ‘Hot Trainers’ table uses Strike Rate (winners to runners) over the last 14 days , whilst the ‘In Form’ table in the ‘Trainerspot GB’ table uses Run To Form, again over the last fortnight. Neither table is useful. Both are based upon too few runners to be able to draw any meaningful conclusions. These tables are an excellent example of attempting to draw inference from a small information set – whilst this instinct helped us survive when faced with perceived mortal dangers in the past, the very same instincts are likely to mislead in the more prosaic setting of horse racing. Whilst the data in the ‘In Form’ table isn’t useful, this is only because there are too few observations to be able to draw any firm conclusions. However, the idea of considering trainer form as an average or median of how close to form the horses under the trainers care are running makes intuitive sense.
The analysis that underpins this piece was carried out in the R statistical environment accessing Raceform Interactive data focussing on the 2010-11 and 2011-12 National Hunt seasons. Thanks to Simon Rowlands and James Willoughby for their input.
Trainer Form Variable Definitions
The starting point for the analysis that follows is to define and calculate a Run To Form (RTF) variable. RTF is defined as follows: the Racing Post Rating (RPR) achieved by each horse in a race subtracted from the maximum RPR achieved by each horse in its runs up to and including the race in question. A horse has to have run more than three times to qualify for consideration. This filter is used to reduce the influence of lightly raced progressive horses. The maximum value RTF can take is zero.
Trainer Form Absolute (TFA)
The next step is to define and calculate a measure of trainer form. Trainer Form Absolute (TFA) is the median RTF for all the runners of a trainer over a particular time period. Using the 2010-11 National Hunt season Graph 1 shows a histogram of TFA for those trainers that had at least 50 runners over the season. 132 trainers qualified. Note the negative skew. This is a common characteristic of form data in horse racing. It is difficult to run close to form wheras there are many and varied reasons for horses running below form. The negative skew in RTF at the horse level aggregates to negative skew in TFA at the trainer level. Graph 2 shows the same information as a Box Plot.
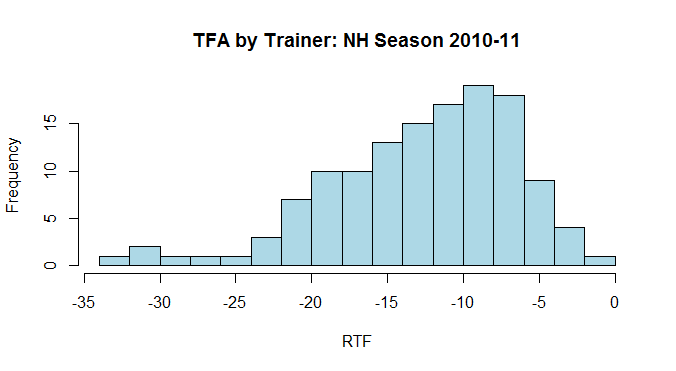
Graph 1: Distribution of trainer TFA NH season 2010-11

Graph 2: Box Plot of trainer TFA NH season 2010-11
So does a ranking of TFA indicate in form trainers at the top and out of form trainers at the bottom? Inspection of Graphs 1 and 2 highlights the problem with using TFA as a measure of trainer form. The range of TFA across trainers is so wide that the top and bottom of the TFA list won’t change often enough to be able to identify trainers in and out of form – for example if Nicky Henderson normally runs at a -5lb TFA and is currently running at -8lb TFA he would still be near the top of the TFA list, wheras he is running 3lb below his normal TFA rate. It is also of note that the variability of TFA per trainer is correlated with their TFA. Either the better horses, who are at the better yards, run more consistently, or the better trainers are able to get their horses, who are better than those elsewhere, to run more consistently. Or a combination of the two. In this context better means those yards with the highest TFA values.
Trainer Form Relative (TFR)
Given the concerns about using TFA a measure of relative run to form can be defined and calculated that takes into account the usual RTF per trainer. Trainer Form Relative (TFR) is defined as the difference between TFA in a particular time period and TFA in a previous time period. TFR enables a direct comparison between trainers with widely different absolute levels of form (TFAs). Now Nicky Henderson’s -3lb TFR can be compared with a trainer whose TFA is normally -12lb and is currently running at -9lb, to give a +3lb TFR.
For the analysis that follows TFR is calculated for each of the seven months October 2011 through to April 2012. TFRs are calculated by taking the TFA in each month by trainer and subtracting the TFA posted by trainer for the previous season 2010-11. So, starting with October 2011, how is its TFR related to the TFRs posted one month later? Graph 3 below shows a significant relationship. At first sight this appears to be clear evidence that trainer form in October 2011 helps predict trainer form in November 2011.

Graph 3: Relationship between TFR October to November 2011
What happens if we compare TFR in October 2011 with months further out? If form is temporary the relationship should decline through time. If October form predicts November form, it shouldn’t predict December form to the same degree. In the jargon we can postulate an autoregressive AR(1) process. What we see in the data is the relationship shown in Graph 3 is as strong between October and November as it is between October and other months. See Table 1 below for correlation coefficients between t and t+1, t+2, t+3 using November 2011 as month t.
Correlation of November 2011 TFR with
December 2011 0.44
January 2012 0.51
February 2012 0.43
March 2012 0.47
April 2012 0.37
Table 1: Correlation of TFR months t with t+1, t+2, t+3 etc
We shouldn’t observe the same level of correlation across the months. It suggests form has a permanent component to it – an oxymoron. So how to explain this result? Imagine we can fast forward one year. We calculate TFA per trainer based upon the season 2011-12. This enables us to compare the results of a trainer in 2010-11 with the next season 2011-12. If we classify TFR as ABOVE or BELOW zero, and then further classify according to whether a trainer had a BETTER or WORSE season in 2011-12 relative to 2010-11, we see how RTF looks month by month in Table 2 below.
BETTER 2011-12 form WORSE 2011-12 form
ABOVE BELOW ABOVE BELOW
ABOVE 76 42 8 28
BELOW 33 16 29 109
Table 2: classification of form by month by year
Remember we have peaked into the future in calculating Table 2. It isn’t available until the end of the second season. The number of observations in the ABOVE-ABOVE and BELOW-BELOW categories are too high for the TFR measure to be useful as an indicator of form. In other words when a trainer is ABOVE or BELOW form in a particular month it is likely that they will continue in that category for the next month and the next month after that and for the duration of the season. The problem here is that the comparison used in the TFR calculation, namely the form of the trainer from the previous season, is likely to suffer from bias. For some trainers it will be higher or lower than the true level of form a trainer can expect, and for those that posted towards the extremes of TFA they are likely to revert back to some degree in the next season. Bias such as this is difficult to remove and as a result relative measures of trainer form such as TFR are as flawed in their own way as absolute measures of trainer from such as TFA.
Summary
I started this analysis with the prior view that trainer form probably exists. My view now is that it if it does exist it is very difficult to measure. Absolute measures of trainer form do not exhibit enough variability, wheras relative measures have problems in deciding on an appropriate comparison. For some the measures of trainer form defined above might be too simplistic, arguing that more complex definitions are required. This is entirely possible. But as complexity of definition increases, particularly if it is one of many derivations tried, so does the risk that the measure will work only for the sample of data on which it was tried. If you torture the data for long enough it will tell you anything.
There is another possible use of trainer form – but more in how it is perceived by the market. Consider Graph 4 below. It shows TFA on the x-axis and Strike Rate on the y-axis by trainer for the 2010-11 season. It is the same data expressed in different ways.
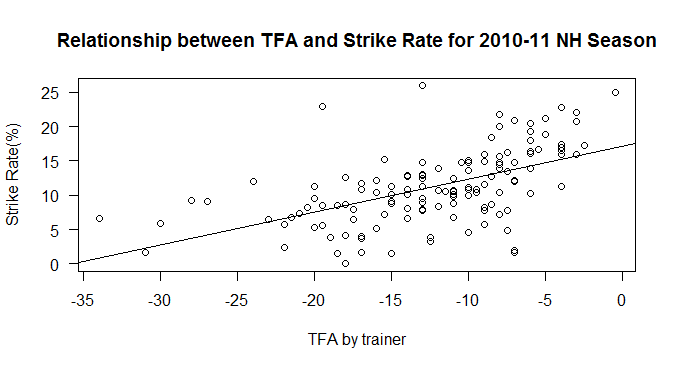
Graph 4: Strike Rate vs trainer form
Strike Rate is a popular measure of form, RTF (and its variants TFA and TFR) less so. Yet Strike Rate is noisier and contains less information than RTF. Given the popularity of trainer form as an idea, and the popularity of Strike Rate as a proxy for trainer form, it is possible that the runners of trainers with a high/low Strike Rate relative to their TFA could have odds that are too far away from their correct values as the market considers these trainers, based upon a faulty premise, to be in or out of form. Armed with the appropriate data this is a testable proposition.