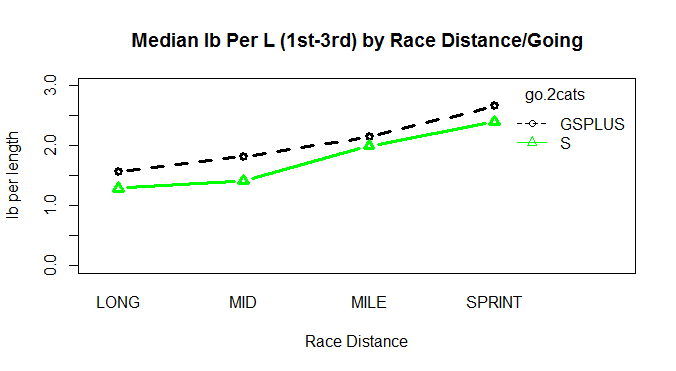
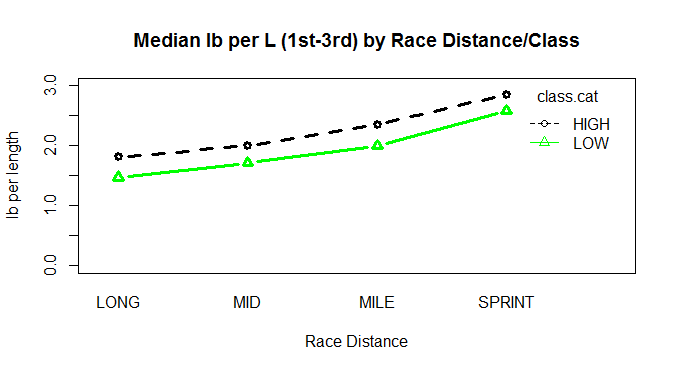
####################################################################
#
#
# Measuring Training Yard Success: Impact Values from Maidens, Handicaps and Pattern Races
# J. Hathorn
#
# v1.0
#
#
# written 18-Sep-13
#
#
###################################################################
#rm(list=ls())
library(foreign)
library(maptools)
# read in database files from RI
#
setwd(“C:/Program Files (x86)/RaceForm Interactive”)
RIhorse.data <-read.dbf(“horse.dbf”)
RIouting.data <-read.dbf(“outing.dbf”)
RIrace.data <-read.dbf(“race.dbf”)
RIsire.data <-read.dbf(“sire.dbf”)
RItrainer.data <- read.dbf(“trainer.dbf”)
RIcourse.data<-read.dbf(“course.dbf”)
# #############################################################
# set date parameters to focus on races between chosen dates
# flat season Lincoln to the November Handicap
chosenDateSt<-c(“2012-03-31”)
chosenDateEd<-c(“2012-11-10”)
# set dates for determining yard sizes, set the previous year to the November Handicap
#chosenDateSt1<-c(“2011-11-11”)
#chosenDateEd1<-c(“2012-11-10”)
#################################################
#
# extract GB course id list from course db
z<-which(RIcourse.data$CCOUNTRY == “GB”)
GBcourseids<-RIcourse.data$CID[z]
GBcoursenames<-RIcourse.data$CNAME[z]
#
# extract GB/IRE trainer lists from trainer db
z<-which(RItrainer.data$TCOUNTRY == “GB”)
GBtrainers<-RItrainer.data$TID[z]
z<-which(RItrainer.data$TCOUNTRY == “IRE”)
IREtrainers<-RItrainer.data$TID[z]
GBIREtrainers<-append(GBtrainers,IREtrainers)
#
#
##################################################
# select outings on the flat between the chosen dates
tmpidx<-which(RIouting.data$ODATE>=chosenDateSt & RIouting.data$ODATE<=chosenDateEd & RIouting.data$OFJ==”F”)
T1.data<-RIouting.data[tmpidx,]
# match the course and add a country variable
z<-match(T1.data$OCOURSEID,RIcourse.data$CID)
T1.data$COCOUNTRY<-NA
T1.data$COCOUNTRY<-RIcourse.data$CCOUNTRY[z]
T1a.data<-T1.data
# select outings that took place on GB courses and append the 2 d f
tmpidx<-which(T1.data$COCOUNTRY == “GB”)
T1.data<-T1.data[tmpidx,]
# #######################
# GB races only
# code to include IRE races if so desired
#tmpidx<-which(T1a.data$COCOUNTRY == “IRE”)
#T2.data<-T1a.data[tmpidx,]
#T1.data<-rbind(T1.data,T2.data)
# ######################
# age restriction if required
# reduce T1 to horses of the desired age given by the parameter agecheck
#agecheck<-2
#tmpidx<-which(T1.data$OAGE==agecheck)
#T1.data<-T1.data[tmpidx,]
# match each horse into the RIhorse d f to get the sire id
z<-match(T1.data$OHORSEID,RIhorse.data$HID)
T1.data$SIREID<-RIhorse.data$HSIREID[z]
# attach some of the race conditions ie age, stakes, handicap etc from the RIrace d f
z<-match(T1.data$ORACEID,RIrace.data$RID)
T1.data$RCOND<-RIrace.data$RCOND[z]
T1.data$RAGE<-RIrace.data$RAGE[z]
T1.data$RANIMAL<-RIrace.data$RANIMAL[z]
T1.data$RPATTERN<-RIrace.data$RPATTERN[z]
T1.data$RISHCAP<-RIrace.data$RISHCAP[z]
# set a 1/0 variable for winners and a 1 variable for runners will help aggregation later
T1.data$runner<-1
T1.data$winner<-0
z<-which(T1.data$OPOS==1)
T1.data$winner[z]<-1
# SP turned into a probability
T1.data$SPprob<-1/(1+T1.data$OSPVAL)
# reformat the ORF rating variable
T1.data$ORF<-as.character(T1.data$ORF)
T1.data$ORF<-gsub(“\\?”,””,T1.data$ORF)
T1.data$ORF<-gsub(“\\+”,””,T1.data$ORF)
T1.data$ORF<-as.numeric(T1.data$ORF)
tmpidx<-which(T1.data$ORF==0)
T1.data$ORF[tmpidx]<-NA
# reformat the OJC rating variable
T1.data$OJC<-as.character(T1.data$OJC)
T1.data$OJC<-gsub(“\\?”,””,T1.data$OJC)
T1.data$OJC<-gsub(“\\+”,””,T1.data$OJC)
T1.data$OJC<-as.numeric(T1.data$OJC)
tmpidx<-which(T1.data$OJC==0)
T1.data$OJC[tmpidx]<-NA
####################################################
#
# produce summary variables by horse – runs/wins/ratings etc
#
hid<-tapply(T1.data$OHORSEID,T1.data$OHORSEID,mean,na.rm=TRUE)
hruns<-tapply(T1.data$runner,T1.data$OHORSEID,sum,na.rm=TRUE)
hwins<-tapply(T1.data$winner,T1.data$OHORSEID,sum,na.rm=TRUE)
hwinner<-pmin(1,hwins)
hrunner<-pmin(1,hruns)
hORmax<-tapply(T1.data$OJC,T1.data$OHORSEID,max,na.rm=TRUE)
hRFmax<-tapply(T1.data$ORF,T1.data$OHORSEID,max,na.rm=TRUE)
z<-which(hORmax==-Inf)
hORmax[z]<-NA
z<-which(hRFmax==-Inf)
hRFmax[z]<-NA
z<-match(hid,T1.data$OHORSEID)
htrainerid<-T1.data$OTRAINERID[z]
z<-match(hid,RIhorse.data$HID)
hname<-RIhorse.data$HNAME[z]
# put these into a d f
HSummary<-data.frame(hid,hname,htrainerid,hruns,hwins,hwinner,hrunner,hORmax,hRFmax)
# ###############
# produce population wide summary stats
univ.OR.med<-median(HSummary$hORmax,na.rm=TRUE)
univ.RF.med<-median(HSummary$hRFmax,na.rm=TRUE)
univ.RF.sd<-sd(HSummary$hRFmax,na.rm=TRUE)
univ.RF.1sdup<-univ.RF.med+univ.RF.sd
univ.winners<-sum(HSummary$hwinner)
univ.runners<-sum(HSummary$hrunner)
univ.winpct<-univ.winners/univ.runners
HSummary$hRF1sdup<-0
z<-which(HSummary$hRFmax>univ.RF.1sdup)
HSummary$hRF1sdup[z]<-1
univ.RF.1sduppct<-sum(HSummary$hRF1sdup)/univ.runners
# ######################################################
#
# now take the horse summary df and produce a trainer summary based upon the horse summary d f
trainer.h<-tapply(HSummary$htrainerid,HSummary$htrainerid,mean,rm=TRUE)
wins.h<-tapply(HSummary$hwins,HSummary$htrainerid,sum,na.rm=TRUE)
runs.h<-tapply(HSummary$hruns,HSummary$htrainerid,sum,na.rm=TRUE)
winspct.h<-wins.h/runs.h
winner.h<-tapply(HSummary$hwinner,HSummary$htrainerid,sum,na.rm=TRUE)
runner.h<-tapply(HSummary$hrunner,HSummary$htrainerid,sum,na.rm=TRUE)
winpct.h<-winner.h/runner.h
#ORmax.med.h<-tapply(HSummary$hORmax,HSummary$htrainerid,median,na.rm=TRUE)
RFmax.med.h<-tapply(HSummary$hRFmax,HSummary$htrainerid,median,na.rm=TRUE)
RFmax.sd.h<-tapply(HSummary$hRFmax,HSummary$htrainerid,sd,na.rm=TRUE)
RFmax.up1sd.h<-RFmax.med.h+RFmax.sd.h
RF.1sdup.h<-tapply(HSummary$hRF1sdup,HSummary$htrainerid,sum,na.rm=TRUE)
RF.1sduppct.h<-RF.1sdup.h/runner.h
TrainerHorses<-data.frame(trainer.h,wins.h,runs.h,winspct.h,winner.h,runner.h,winpct.h,RFmax.med.h,RFmax.sd.h,RFmax.up1sd.h,RF.1sdup.h,RF.1sduppct.h)
z<-match(TrainerHorses$trainer.h,RItrainer.data$TID)
TrainerHorses$tname.h<-RItrainer.data$TSTYLENAME[z]
# write out this d f to a CSV file
#fname<-“c:/Racing Research/Trainer Research/trainerhorses.csv”
#write.csv(TrainerHorses,file=fname)
# ####################################################
#
# now go back to the Outing d f and split into race categories to get IVs etc by trainer
#
# split the races into different data frames
# Maidens
# Handicaps
# Pattern
# ###################################################
#
# put maidens into their own d f
z<-which(T1.data$RANIMAL==”MDN”)
T2.data<-T1.data[z,]
# set up Sire IVs in maidens
sire.ID<-tapply(T2.data$SIREID,T2.data$SIREID,mean,na.rm=TRUE)
sire.wins <- tapply(T2.data$winner,T2.data$SIREID,sum,na.rm=TRUE)
total.wins<-sum(sire.wins)
sire.runs <- tapply(T2.data$runner,T2.data$SIREID,sum,na.rm=TRUE)
total.runs<-sum(sire.runs)
sire.IV<-(sire.wins/total.wins)/(sire.runs/total.runs)
# bring sire IV back into the T2 d f and calc a sire adjusted run variable
z<-match(T2.data$SIREID,sire.ID)
T2.data$sire.IV<-sire.IV[z]
T2.data$runner.SA<-T2.data$runner*T2.data$sire.IV
# calc the trainer IVs in maidens
trainerID<-tapply(T2.data$OTRAINERID,T2.data$OTRAINERID,mean,na.rm=TRUE)
trainer.wins <- tapply(T2.data$winner,T2.data$OTRAINERID,sum,na.rm=TRUE)
total.wins<-sum(trainer.wins)
trainer.runs <- tapply(T2.data$runner,T2.data$OTRAINERID,sum,na.rm=TRUE)
trainer.runs.SA <- tapply(T2.data$runner.SA,T2.data$OTRAINERID,sum,na.rm=TRUE)
total.runs<-sum(trainer.runs)
total.runs.SA<-sum(trainer.runs.SA)
trainer.IV<-(trainer.wins/total.wins)/(trainer.runs/total.runs)
trainer.IV.SA<-(trainer.wins/total.wins)/(trainer.runs.SA/total.runs.SA)
#copy over to maiden specific variables
wins.mdns<-trainer.wins
runs.mdns<-trainer.runs
runs.mdns.SA<-trainer.runs.SA
IV.mdns<-trainer.IV
IV.SA.mdns<-trainer.IV.SA
# put into a maiden trainer summary d f
TrainerMdns<-data.frame(trainerID,wins.mdns,runs.mdns,runs.mdns.SA,IV.mdns,IV.SA.mdns)
# #####################################################
#
# put handicaps into their own d f
z<-which(T1.data$RISHCAP==”TRUE”)
T2.data<-T1.data[z,]
# set up Sire IVs in maidens
sire.ID<-tapply(T2.data$SIREID,T2.data$SIREID,mean,na.rm=TRUE)
sire.wins <- tapply(T2.data$winner,T2.data$SIREID,sum,na.rm=TRUE)
total.wins<-sum(sire.wins)
sire.runs <- tapply(T2.data$runner,T2.data$SIREID,sum,na.rm=TRUE)
total.runs<-sum(sire.runs)
sire.IV<-(sire.wins/total.wins)/(sire.runs/total.runs)
# bring sire IV back into the T2 d f and calc a sire adjusted run variable
z<-match(T2.data$SIREID,sire.ID)
T2.data$sire.IV<-sire.IV[z]
T2.data$runner.SA<-T2.data$runner*T2.data$sire.IV
# calc the trainer IVs in handicaps
trainerID<-tapply(T2.data$OTRAINERID,T2.data$OTRAINERID,mean,na.rm=TRUE)
trainer.wins <- tapply(T2.data$winner,T2.data$OTRAINERID,sum,na.rm=TRUE)
total.wins<-sum(trainer.wins)
trainer.runs <- tapply(T2.data$runner,T2.data$OTRAINERID,sum,na.rm=TRUE)
trainer.runs.SA <- tapply(T2.data$runner.SA,T2.data$OTRAINERID,sum,na.rm=TRUE)
total.runs<-sum(trainer.runs)
total.runs.SA<-sum(trainer.runs.SA)
trainer.IV<-(trainer.wins/total.wins)/(trainer.runs/total.runs)
trainer.IV.SA<-(trainer.wins/total.wins)/(trainer.runs.SA/total.runs.SA)
#copy over to handicap specific variables
wins.hcaps<-trainer.wins
runs.hcaps<-trainer.runs
runs.hcaps.SA<-trainer.runs.SA
IV.hcaps<-trainer.IV
IV.SA.hcaps<-trainer.IV.SA
# put into a handicap trainer summary d f
TrainerHcaps<-data.frame(trainerID,wins.hcaps,runs.hcaps,runs.hcaps.SA,IV.hcaps,IV.SA.hcaps)
# ###################################################
#
# put patterns into their own d f
z<-which(T1.data$RPATTERN !=”NOT” & T1.data$RISHCAP == “FALSE”)
T2.data<-T1.data[z,]
# set up Sire IVs in patterns
sire.ID<-tapply(T2.data$SIREID,T2.data$SIREID,mean,na.rm=TRUE)
sire.wins <- tapply(T2.data$winner,T2.data$SIREID,sum,na.rm=TRUE)
total.wins<-sum(sire.wins)
sire.runs <- tapply(T2.data$runner,T2.data$SIREID,sum,na.rm=TRUE)
total.runs<-sum(sire.runs)
sire.IV<-(sire.wins/total.wins)/(sire.runs/total.runs)
# bring sire IV back into the T2 d f and calc a sire adjusted run variable
z<-match(T2.data$SIREID,sire.ID)
T2.data$sire.IV<-sire.IV[z]
T2.data$runner.SA<-T2.data$runner*T2.data$sire.IV
# calc the trainer IVs in patterns
trainerID<-tapply(T2.data$OTRAINERID,T2.data$OTRAINERID,mean,na.rm=TRUE)
trainer.wins <- tapply(T2.data$winner,T2.data$OTRAINERID,sum,na.rm=TRUE)
total.wins<-sum(trainer.wins)
trainer.runs <- tapply(T2.data$runner,T2.data$OTRAINERID,sum,na.rm=TRUE)
trainer.runs.SA <- tapply(T2.data$runner.SA,T2.data$OTRAINERID,sum,na.rm=TRUE)
total.runs<-sum(trainer.runs)
total.runs.SA<-sum(trainer.runs.SA)
trainer.IV<-(trainer.wins/total.wins)/(trainer.runs/total.runs)
trainer.IV.SA<-(trainer.wins/total.wins)/(trainer.runs.SA/total.runs.SA)
#copy over to pattern specific variables
wins.ptns<-trainer.wins
runs.ptns<-trainer.runs
runs.ptns.SA<-trainer.runs.SA
IV.ptns<-trainer.IV
IV.SA.ptns<-trainer.IV.SA
# put into a pattern trainer summary d f
TrainerPtns<-data.frame(trainerID,wins.ptns,runs.ptns,runs.ptns.SA,IV.ptns,IV.SA.ptns)
# ###################################################
#
# merge the trainer summary d f s
#
Temp<-merge(TrainerMdns,TrainerHcaps,by.x=”trainerID”,by.y=”trainerID”,all.x=”TRUE”,all.y=”TRUE”)
Trainers<-merge(Temp,TrainerPtns,by.x=”trainerID”,by.y=”trainerID”,all.x=”TRUE”,all.y=”TRUE”)
z<-match(Trainers$trainerID,RItrainer.data$TID)
Trainers$tname<-RItrainer.data$TSTYLENAME[z]
Trainers$country<-RItrainer.data$TCOUNTRY[z]
# merge in the ratings d f
#
TrainersAll<-merge(Trainers,TrainerHorses,by.x=”trainerID”,by.y=”trainer.h”,all.x=TRUE,all.y=TRUE)
#
#
# clean up soome of the variables, replace NA by 0
#
z<-which(is.na(TrainersAll$runs.mdns))
TrainersAll$runs.mdns[z]<-0
z<-which(is.na(TrainersAll$runs.hcaps))
TrainersAll$runs.hcaps[z]<-0
z<-which(is.na(TrainersAll$runs.ptns))
TrainersAll$runs.ptns[z]<-0
z<-which(is.na(TrainersAll$runs.mdns.SA))
TrainersAll$runs.mdns.SA[z]<-0
z<-which(is.na(TrainersAll$runs.hcaps.SA))
TrainersAll$runs.hcaps.SA[z]<-0
z<-which(is.na(TrainersAll$runs.ptns.SA))
TrainersAll$runs.ptns.SA[z]<-0
z<-which(is.na(TrainersAll$wins.mdns))
TrainersAll$wins.mdns[z]<-0
z<-which(is.na(TrainersAll$wins.hcaps))
TrainersAll$wins.hcaps[z]<-0
z<-which(is.na(TrainersAll$wins.ptns))
TrainersAll$wins.ptns[z]<-0
z<-which(is.na(TrainersAll$IV.mdns))
TrainersAll$IV.mdns[z]<-0
z<-which(is.na(TrainersAll$IV.SA.mdns))
TrainersAll$IV.SA.mdns[z]<-0
z<-which(is.na(TrainersAll$IV.hcaps))
TrainersAll$IV.hcaps[z]<-0
z<-which(is.na(TrainersAll$IV.SA.hcaps))
TrainersAll$IV.SA.hcaps[z]<-0
z<-which(is.na(TrainersAll$IV.ptns))
TrainersAll$IV.ptns[z]<-0
z<-which(is.na(TrainersAll$IV.SA.ptns))
TrainersAll$IV.SA.ptns[z]<-0
TrainersAll$wins.all<-TrainersAll$wins.mdns+TrainersAll$wins.hcaps+TrainersAll$wins.ptns
TrainersAll$runs.all<-TrainersAll$runs.mdns+TrainersAll$runs.hcaps+TrainersAll$runs.ptns
TrainersAll$runs.all.SA<-TrainersAll$runs.mdns.SA+TrainersAll$runs.hcaps.SA+TrainersAll$runs.ptns.SA
# produce summary stats
#
# composite IVs weighted by all runs in maidens, handicaps and pattern races
TrainersAll$IVcomp1<-(TrainersAll$IV.mdns*sum(TrainersAll$runs.mdns,na.rm=TRUE)+TrainersAll$IV.hcaps*sum(TrainersAll$runs.hcaps,na.rm=TRUE)
+TrainersAll$IV.ptns*sum(TrainersAll$runs.ptns,na.rm=TRUE))/(sum(TrainersAll$runs.mdns,na.rm=TRUE)+sum(TrainersAll$runs.hcaps,na.rm=TRUE)+sum(TrainersAll$runs.ptns,na.rm=TRUE))
TrainersAll$IVcomp1.SA<-(TrainersAll$IV.SA.mdns*sum(TrainersAll$runs.mdns.SA,na.rm=TRUE)+TrainersAll$IV.SA.hcaps*sum(TrainersAll$runs.hcaps.SA,na.rm=TRUE)
+TrainersAll$IV.SA.ptns*sum(TrainersAll$runs.ptns.SA,na.rm=TRUE))/(sum(TrainersAll$runs.mdns.SA,na.rm=TRUE)+sum(TrainersAll$runs.hcaps.SA,na.rm=TRUE)+sum(TrainersAll$runs.ptns.SA,na.rm=TRUE))
TrainersAll$IVcomp2<-(TrainersAll$IV.mdns*TrainersAll$runs.mdns+TrainersAll$IV.hcaps*TrainersAll$runs.hcaps
+TrainersAll$IV.ptns*TrainersAll$runs.ptns)/(TrainersAll$runs.mdns+TrainersAll$runs.hcaps+TrainersAll$runs.ptns)
TrainersAll$IVcomp2.SA<-(TrainersAll$IV.SA.mdns*TrainersAll$runs.mdns.SA+TrainersAll$IV.SA.hcaps*TrainersAll$runs.hcaps.SA
+TrainersAll$IV.SA.ptns*TrainersAll$runs.ptns.SA)/(TrainersAll$runs.mdns.SA+TrainersAll$runs.hcaps.SA+TrainersAll$runs.ptns.SA)
# difference variables, hcaps – mdns
TrainersAll$IVdiff.hcapsmdns<-TrainersAll$IV.hcaps-TrainersAll$IV.mdns
TrainersAll$IVdiff.hcapsmdns.SA<-TrainersAll$IV.SA.hcaps-TrainersAll$IV.SA.mdns
# quality differences using composites
TrainersAll$IVdiff.comp1.SAraw<-TrainersAll$IVcomp1.SA-TrainersAll$IVcomp1
TrainersAll$IVdiff.comp2.SAraw<-TrainersAll$IVcomp2.SA-TrainersAll$IVcomp2
# reduce the list to those trainers that have had >=50 runs in handicaps and are GB based and more than 2*50 runs in total
minruns<-50
z<-which(TrainersAll$runs.hcaps >= minruns & TrainersAll$country==”GB” & TrainersAll$runs.all >= 2*minruns)
Temp<-TrainersAll[z,]
TrainersAll50GB<-Temp[order(-Temp$IVcomp2.SA),]
# write out this d f to a CSV file
fname<-“c:/Racing Research/Trainer Research/trainersall50gb.csv”
write.csv(TrainersAll50GB,file=fname)
slcutoff<-40
z<-which(TrainersAll50GB$runner.h < slcutoff)
TrainersSmall50GB<-TrainersAll50GB[z,]
fname<-“c:/Racing Research/Trainer Research/trainerssmall50gb.csv”
write.csv(TrainersSmall50GB,file=fname)
z<-which(TrainersAll50GB$runner.h >= slcutoff)
TrainersLarge50GB<-TrainersAll50GB[z,]
fname<-“c:/Racing Research/Trainer Research/trainerslarge50gb.csv”
write.csv(TrainersLarge50GB,file=fname)